一、核心构想 (Core Idea)
Autoresearch 本质上是一个由 LLM Agent 驱动的简易受限优化循环(Constrained Optimization Loop)。Agent 通过从 program.md 中读取指令,不断修改单一文件(train.py)来迭代优化特定的评估指标(eval metric)。我额外增加了一个 scratchpad.md 文件,作为 Agent 的工作内存(Working Memory),用于记录其思维过程和实验数据。
在 program.md 中,我将探索过程分成了几个“阶段”:从显而易见的超参数调优(Hyperparameter Tuning)开始,逐渐过渡到小型的模型架构调整,最后再到一些“异想天开”的尝试(Moonshot Ideas)。在最后的阶段,我几乎放开了所有约束,赋予了 Agent 联网权限,让它去阅读论文并寻找新的想法(Look for new Ideas)。
整个流程是一个极其紧凑的闭环:提出假设 → 修改代码 → 训练 → 评估 → 提交或回滚 → 重复。
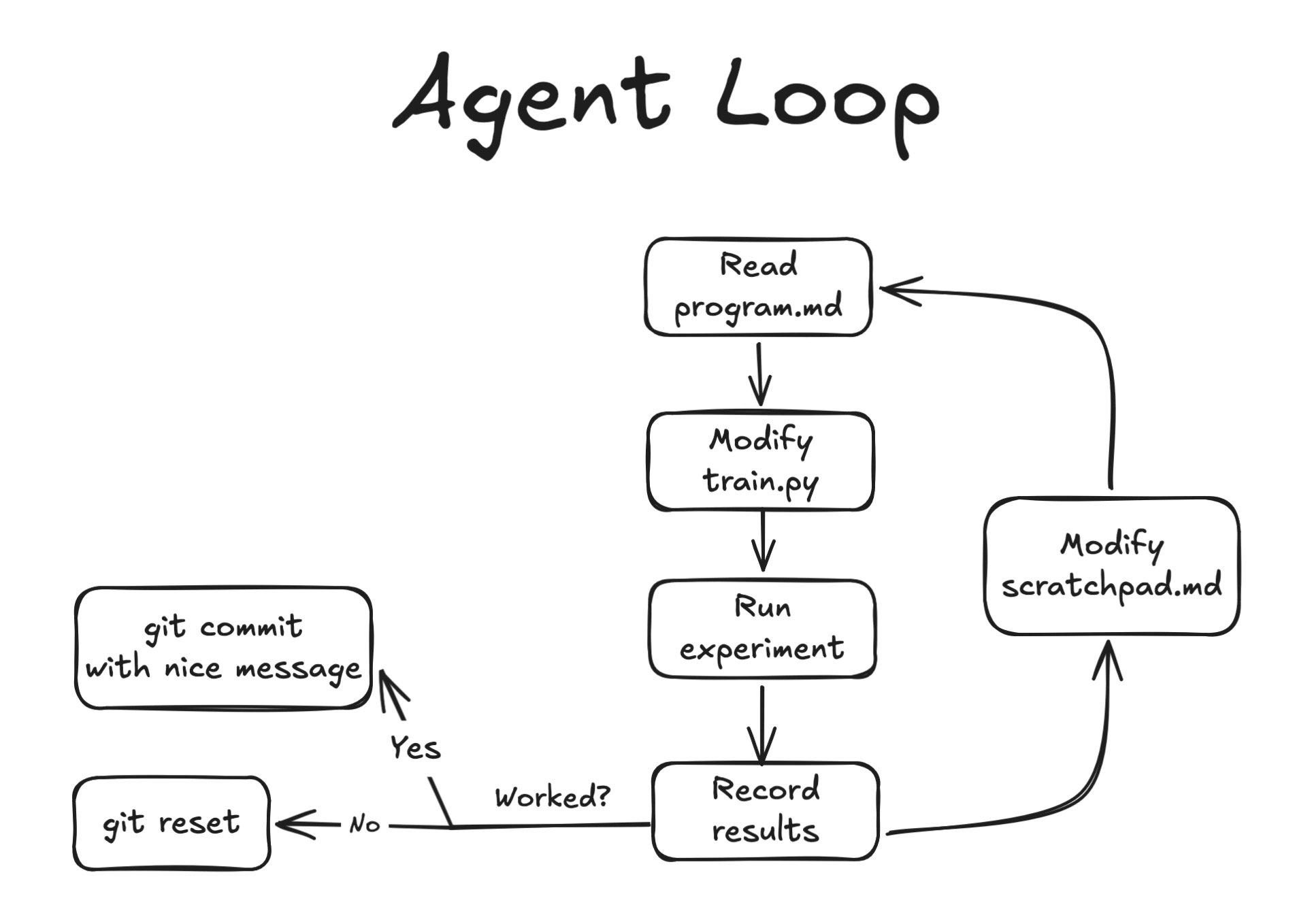
为了鼓励快速迭代并防止对噪声过拟合,实验被限制在每轮约 5 分钟时间。只要在预算时间内,Agent 可以自由修改 train.py 中的任何内容。
二、沙盒机制 (Sandboxing)
由于担心 Agent 在我的工作站上随意运行代码,我将训练循环进行了容器化处理,并禁用了网络访问,整个流程由 run.sh 进行编排调度。随后,我锁定了 Claude Code 的权限,仅允许其修改指定文件并运行 run.sh,禁止其直接执行 Python、禁止 pip install、禁止网络访问及运行 git push 等。
细节我就不在这里赘述了,大家可以直接去仓库看看!三、数据集:Ukiyo-eVG (浮世绘视觉定位)
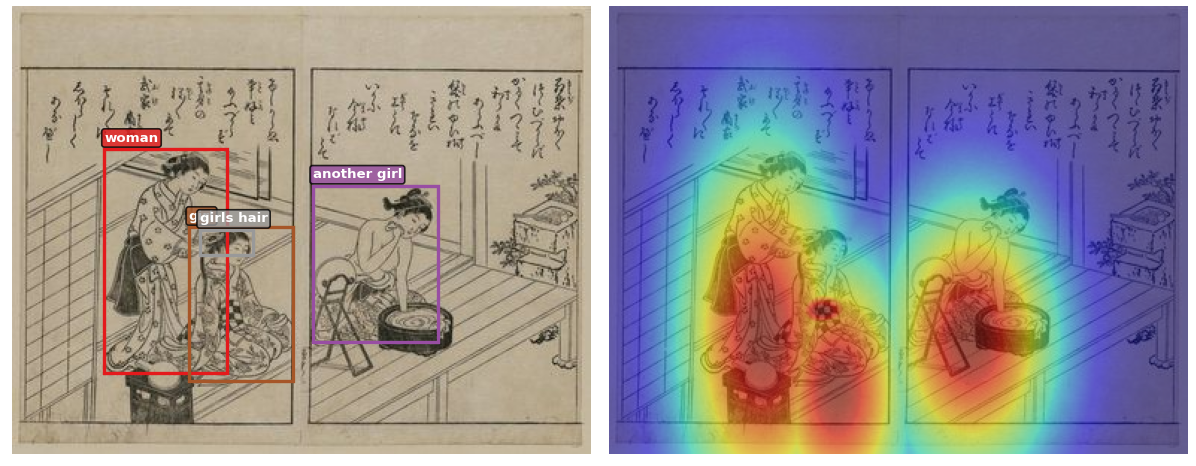
原始论文使用的是医学 X 光数据集,但我现在拿不到访问权限了。为了测试 eCLIP 论文中的专家注意力机制 (Expert Attention),我需要一个带有空间标注的新数据集。我选择了 Ukiyo-eVG:
- 规模: 约 1.1 万张浮世绘木版画。
- 标注: 包含“短语 → 边界框”的对应关系(来自 ECCV 2024 VISART 的 CIGAr 论文)。
- 机制: 通过边界框(Bounding Boxes)生成的空间热图,能够引导模型将注意力精准聚焦在特定的图像区域。边界框被转换为高斯热图 (Gaussian Heatmaps) 喂给模型作为额外的输入,模拟原 eCLIP 论文中放射科医生视线追踪热图的作用。
四、你好,Claude Code
由于我周末有很多家务要处理,我直接把旧研究代码扔给了 Claude,然后做家务去了。
它升级了旧研究代码的 Python 环境,编写了新数据集的数据加载(Ingestion)代码,并搭建了整个实验循环的脚手架(Scaffolding)。而我在 program.md 中设定交叉验证(CV)的划分逻辑、评估指标的计算逻辑,并构思了初步的实验想法。在评估指标上,我们选择了检索嵌入(Retrieved Embeddings)的平均排名(Mean Rank)。当时我并没深思熟虑——事后看来,中位数排名(Median Rank)其实是更好的选择,因为它对离群点(Outliers)的鲁棒性更强。不过,我们当时只需要一个直观的指标,能明确告诉 Agent 某次改动是变好了还是变坏了。既然最终结果还是要用标准指标 Recall@K 来汇报,Mean Rank 只要能起到“指引正确方向”的作用就足够了。
实验细节配置
- CLIP 骨干架构: ViT-Small (22M) + DistilBERT (66M) + 热图处理器(HeatmapProcessor),总计约 9,000 万(90M)参数。
- 训练配置: 800 个步长(Steps),在 RTX 4090 上单次运行耗时约 3 分钟。
- 评估方式: 在包含 1,000 张图像的留出测试集(Held-out Test Set)上计算平均排名(Mean Rank),并将 Recall@K 作为一致性检查(Sanity Check)。
- 基准值(Baseline): 验证集 Mean Rank 为 344.68;图像→文本(img→txt)的 R@1 为 17.2%,文本→图像(txt→img)的 R@1 为 16.5%。
五、效果究竟如何?
我在周六早上启动了循环,然后任由它运行了一整天,偶尔查看一下进度,给智能体指指方向。当我买完菜回来时,Agent 已经跑了几十组实验,并且大幅削减了评估指标中的平均排名(Mean Rank)。
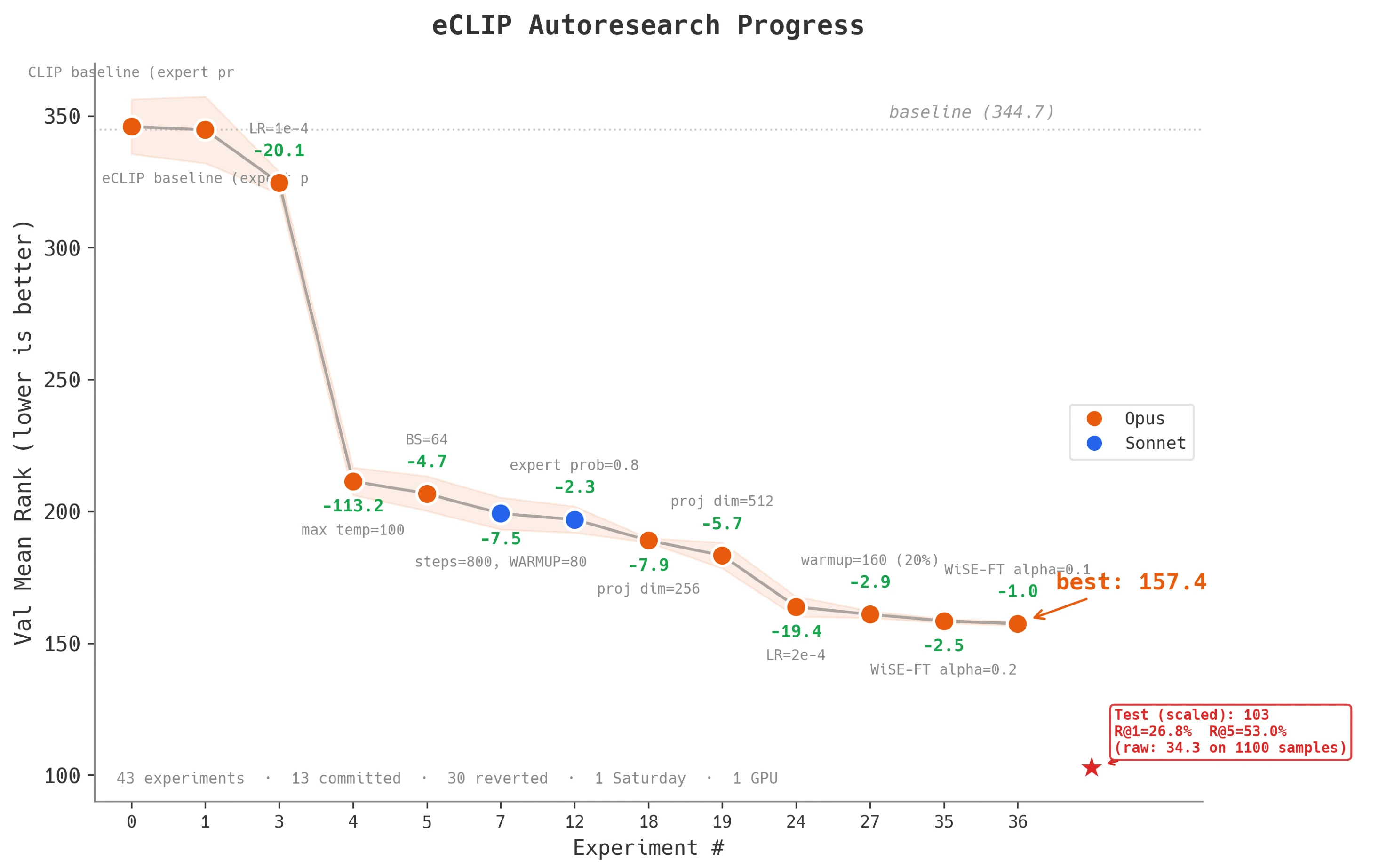
到当天结束时,平均排名从 344.68 降至 157.43。在 Agent 完成探索后,我用全量数据集跑了最后一次训练。结果显示,测试集的分数竟然比验证集还要好。这意味着我们在每轮仅 800 步的短程实验中处于欠拟合(Underfitting)状态,实际上还留有一定的性能提升空间。
| 指标 | Mean Rank | 图像→文本 R@5 | 文本→图像 R@5 |
|---|---|---|---|
| 最终测试 (Test) | 34.30 | 53.0% | 51.4% |
六、所以,这就是 AGI 吗?
嗯…… 还没那么简单:
- 修复温度系数钳位 (-113 Mean Rank): 它一上来就抓住了我代码里的一个 Bug。我之前把可学习的“温度参数(Temperature)”限制在了 2。它放开了这个限制,指标瞬间暴降 113 点。这是单次改进中收益最大的,比所有架构调整加起来都管用。
- Optuna++ (-30 Mean Rank): 进一步的提升主要来自超参数调优。Agent 表现得像一个内置了基础推理能力的超参优化算法。通过增加投影维度并重新微调学习率,指标又降了 30 点。这种活儿虽然无聊且乏味,但 Agent 做得比人类更迅速、更系统。
- 边际效应递减: 到了涉及架构调整的第四阶段,LLM 提出的假设成功率显著下降。它对热图处理器中注意力机制的修改全部宣告失败。至于第五阶段的那些“脑洞想法”,更是一个都没成。Agent 就像在胡乱投石问路,可惜大部分都失败了。
- 沙盒机制至关重要: 接近尾声时,Claude Code 有时会忘记自己的权限,开始执行一些奇怪的 Bash 调用,然后又因为权限受阻而报错并停止循环。有一次它甚至等训练等烦了,直接单方面结束了对话。目前的它还不能完全脱离人类监管。
七、结语
就像所有 LLM 项目一样:前 90% 的工作极其顺滑,几乎不需要我介入;但最后 10% 简直是一场苦战。这是一个非常有趣的实验,展示了 LLM Agent 如何以结构化的方式驱动机器学习研究。
或许,“每项实验仅限一次变动”的限制对于那些大胆的灵感(Moonshot ideas)来说过于严苛了。也许我们应该在 Agent 循环中加入一个规划层,让它具备前瞻性思考的能力;又或者,可以部署一些子 Agent 来协同工作。当然,回头见,期待下次更新。
致谢
- Ukiyo-eVG —— 约 1.1 万张带有“短语→边界框”标注的浮世绘木版画,来自 CIGAr 论文(ECCV 2024 VISART)。
- Autoresearch —— 感谢 Andrej Karpathy 提供的原始创意与灵感启发。