時光流轉,在二十一世紀的今天,人工智慧領域也有一對"雙胞胎"——Pre-Norm(前置歸一化)和 Post-Norm(後置歸一化)。他們為解決大模型訓練穩定性而生,迅速成為 Transformer 架構中用於穩定訊號流的關鍵正規化。
然而,歸一化帶來的訓練穩定性並非沒有代價,兩種歸一化正規化之間似乎面臨著難以調和的權衡取捨。儘管近年來 Pre-Norm 被 GPT-3、LLaMA、DeepSeek、Qwen 等知名開源基座所採用,但多項研究共同指向了一個嚴峻事實:Pre-Norm 架構存在嚴重的"深度失效"問題——大量深層引數雖在參與計算,卻無法拓展模型的表徵能力,致使模型的"有效深度"嚴重受限。與之相對的,儘管從表徵能力角度 Post-Norm 擁有更高潛力,但其訓練不穩定性在現代 Transformer 的預訓練正規化下是毀滅性的。於是,Pre-Norm 與 Post-Norm 這一對為解決同一難題而誕生的雙胞胎,在各自追求"穩定"與"深度"的道路上分道揚鑣。
近日,清華大學黃高 Leap Lab 團隊聯合千問 C 端團隊給出了一份全新的答案 —— SiameseNorm。這一創新的孿生雙流架構,巧妙地解耦了最佳化動力學:它並未在 Pre-Norm 與 Post-Norm 之間做二選一的取捨,而是構建了兩條引數共享的平行通路。在這一架構下,一條流透過 Pre-Norm 機制保證訓練的穩定性,另一條流則利用 Post-Norm 特性極大地釋放模型的表徵潛力。這種設計讓每個殘差塊都能接收到來自兩種正規化的組合梯度,在幾乎不增加計算開銷的前提下,實現了高學習率下的穩定訓練。這一精巧的雙流協作,恰如默契的暹羅雙胞胎,將兩種正規化的對立轉化為深度融合的協同優勢。
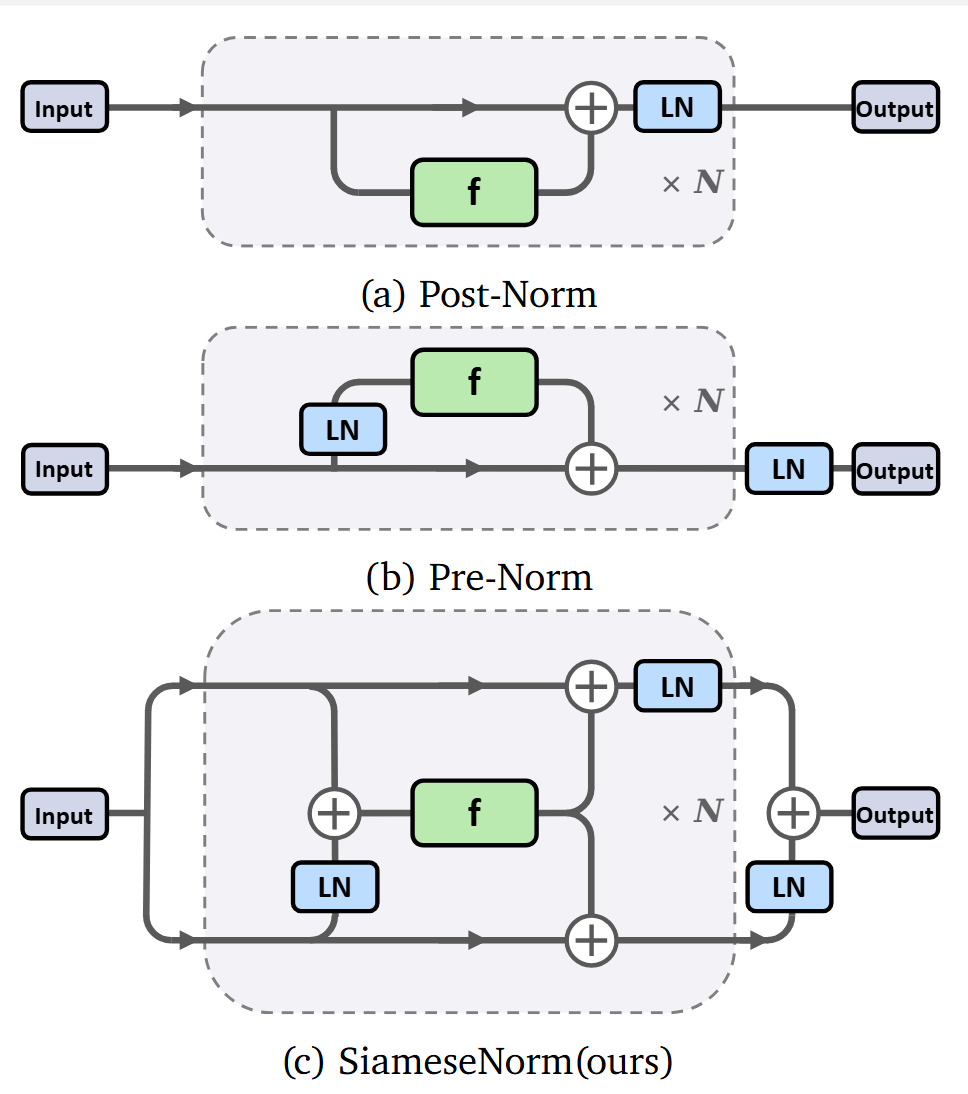
一、困境:單主幹架構的先天缺陷與正規化對立
前置還是後置?這彷彿是 Transformer 世界的"魚與熊掌"。研究者不得不在"訓練穩定但可能平庸"的 Pre-Norm 與"潛力巨大卻難以駕馭"的 Post-Norm 之間做出艱難抉擇。更令人困擾的是,任何試圖在單主幹架構中調和二者的努力,都遭遇了數學上的根本性障礙。
痛點 1:Pre-Norm 的"稀釋"與 Post-Norm 的"畸變"
Transformer 的設計核心在於殘差連線。然而,現有的兩種主流正規化都存在致命的結構性缺陷:
- Pre-Norm(稀釋問題):為了保證梯度暢通,Pre-Norm
保留了一條幹淨的恆等路徑。但這導致主幹流的訊號幅度隨深度巨幅增長。到了深層,層歸一化(LN)後的輸入相對於巨大的主幹流來說微乎其微,導致深層網路的貢獻被"稀釋",模型實際上退化成了"淺層"網路。最直觀的實驗證據來自於層剪枝實驗:將
Pre-Norm 模型 30% 的層直接移除,在零微調的情況下,其評估指標竟幾乎沒有損失。
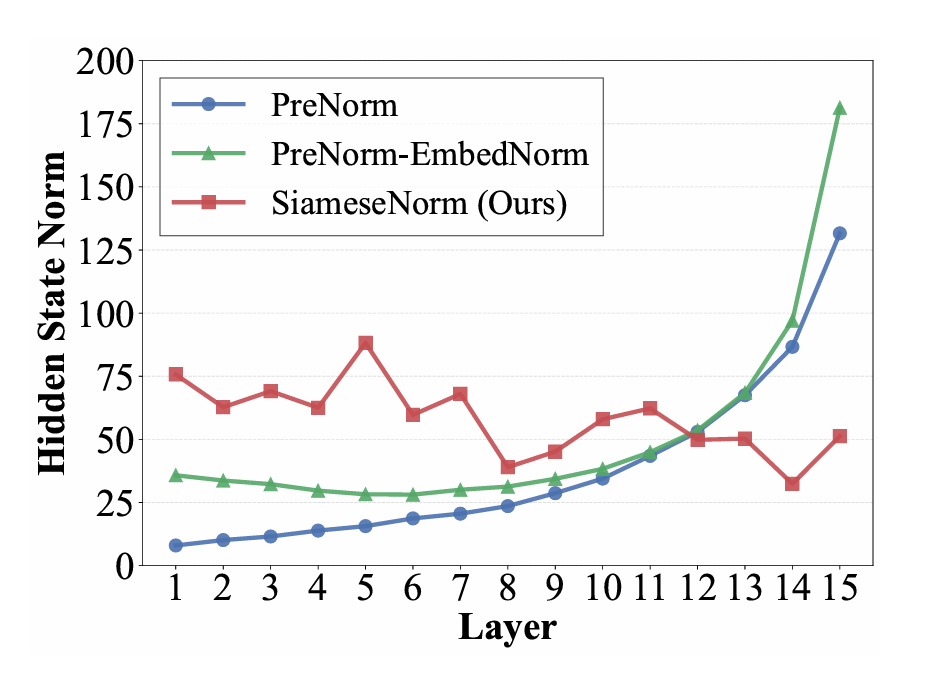
圖2: 不同方法的隱藏狀態範數隨層數的變化曲線,可以看到Pre-Norm架構幾乎是指數級增長 - Post-Norm(畸變問題):Post-Norm 強制在殘差相加後進行歸一化,保證了表示的效率,理論上限更高。但這也意味著它在每一步都在強行"壓縮"訊號,導致梯度的傳導被破壞,容易引發梯度消失或爆炸。
痛點 2:兩大正規化的不可相容性
目前的混合方案試圖在兩者間尋找平衡,但論文深刻地揭示了,這兩種結構在單主幹設計中本質上是互斥的:
- 梯度的"無損傳輸" vs. 訊號的"尺度束縛":Pre-Norm 的穩定性依賴於保留嚴格的恆等路徑,這意味著必須允許訊號幅度在主幹中自然增長。相反,Post-Norm 的高效性依賴於嚴格規範,即在主幹中透過歸一化限制訊號幅度。
- 單主幹的理論極限:論文指出,在共享同一條主幹路徑的前提下,在數學上不可能同時做到兩件事:既保留一條完全乾淨、不受阻礙的梯度通道,又同時對主幹訊號強制施加嚴格的幅度約束。
任何試圖在單主幹結構內強行融合兩者的嘗試,最終都只能是一種"妥協":它們不僅無法兼得二者之長,反而繼承了 Post-Norm 的不穩定性。要打破這個僵局,必須從結構上進行徹底的解耦。
二、破局:SiameseNorm 的雙流解耦之道
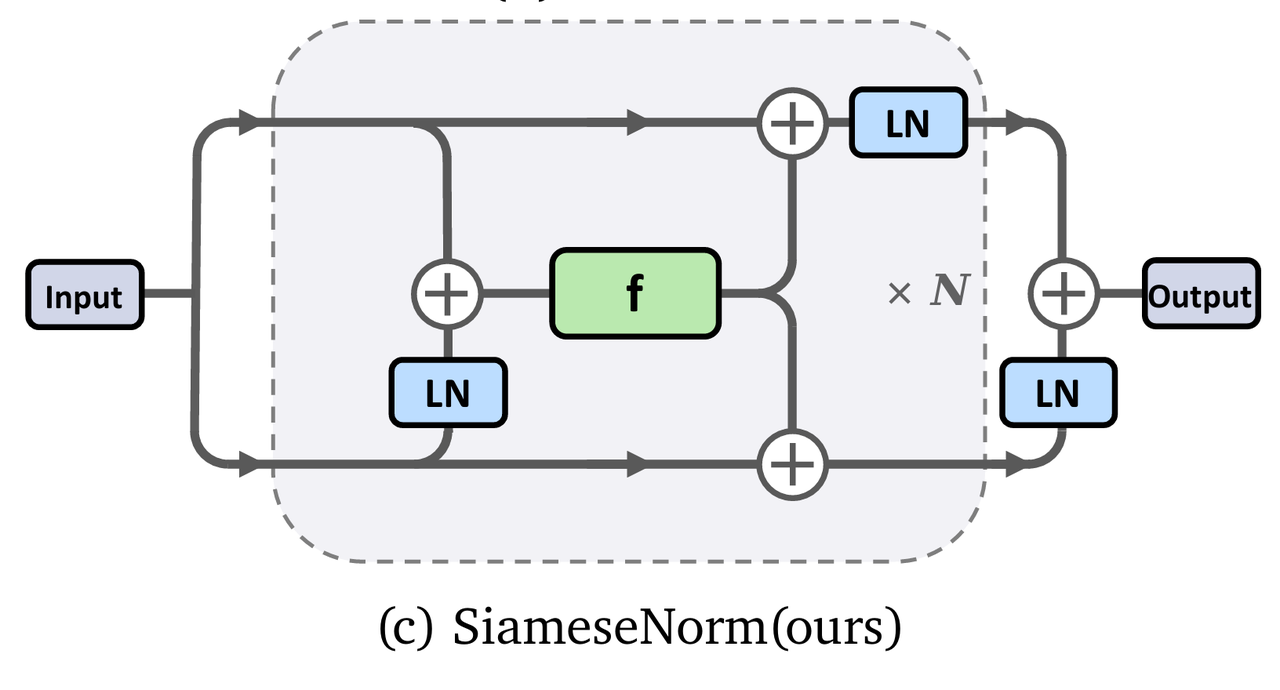
SiameseNorm 的核心洞察在於:我們無法在單一訊號流中同時滿足"梯度傳導"和"表示規範"這兩個互斥的需求。因此,SiameseNorm 引入了"孿生雙流"(Siamese)機制:
從結構圖中也可以看出,把下一半遮住,它退化成 Post-Norm;把上一半遮住,它退化成 Pre-Norm。而在訓練過程中,LayerNorm 的可學習權重可以調整兩條流的大小關係。透過將支流上的 LayerNorm 調整為 0,可以退化成現有的 Pre-Norm、Post-Norm、Mix-LN 正規化。
這一架構的核心在於高效的"引數共享"機制:雙流路徑並非獨立存在,而是共享殘差塊的權重。這意味著 SiameseNorm 幾乎沒有帶來引數量與計算的增長。為降低這種耦合結構的訓練難度,架構中進一步引入了 Normalized Input(歸一化輸入) 與 Depth-wise Scaling(深度縮放),有效解決了引數共享的雙流架構帶來的最佳化對齊挑戰。
三、硬核實測:拯救 Post-Norm,數學任務暴漲 40%
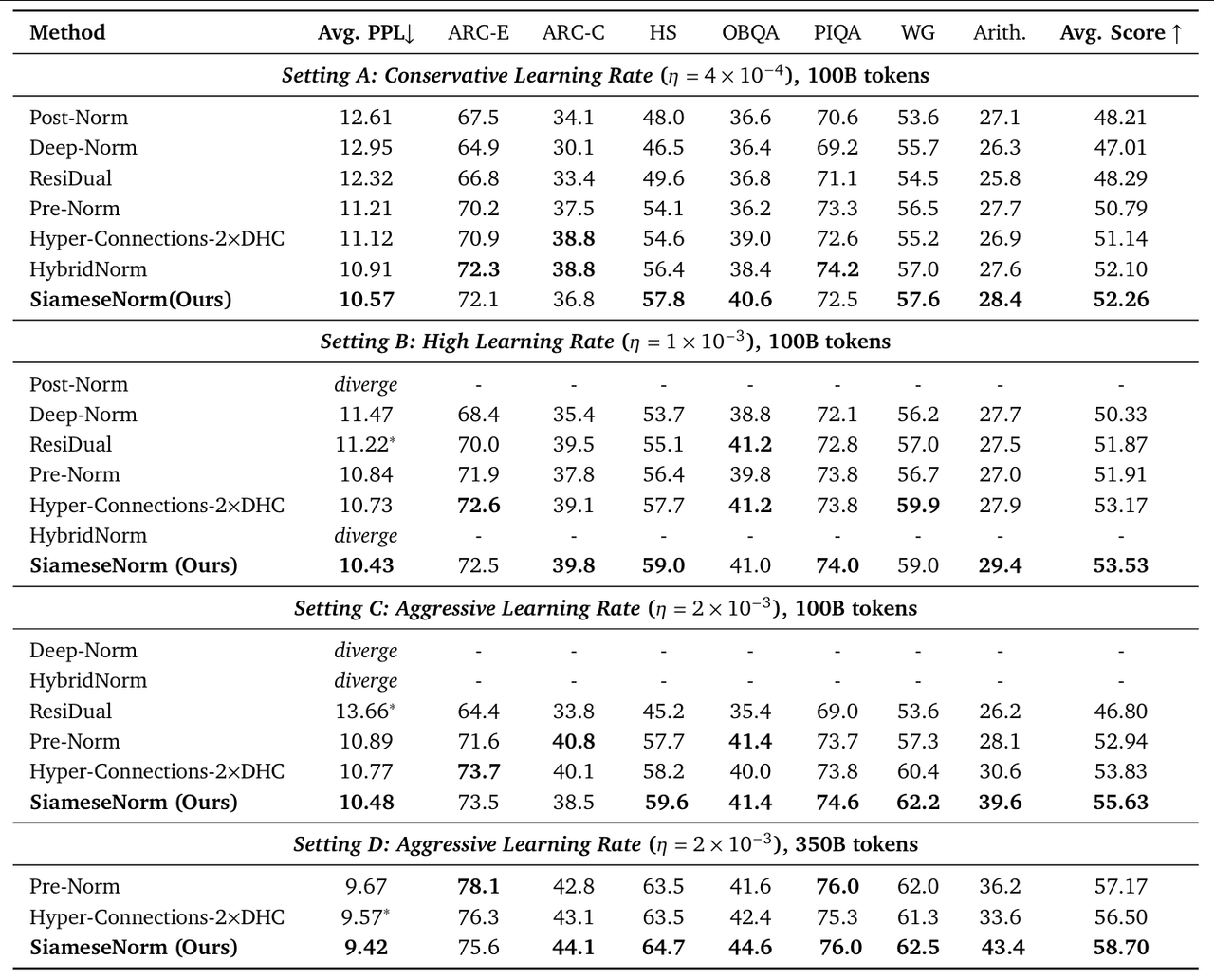
在 1.3B 引數模型、100B/350B tokens、總計算成本超過 50,000 A100 GPU 小時的預訓練實驗中,SiameseNorm 展現了驚人的統治力:
直面公平對比的挑戰
研究者首先在不同的學習率下對比了現有各種 Pre-Norm 和 Post-Norm/HybridNorm 變體的表現,發現兩類正規化的最優學習率存在顯著差異,這揭示了一個長期被忽視的問題:超參(尤其學習率)的選擇足以改變架構對比的結論。換言之,過往許多研究因未能適配 Pre-Norm 的最優配置,實際上人為地壓低了基線的效能天花板,從而製造了"效能顯著提升"的假象。
因此,一個公平的比較應該對不同方法分別做超參搜尋,而這在大模型預訓練中成本極高。在本篇論文中,研究者直接沿用了主流 Pre-Norm 的訓練超參。這一策略旨在證明,SiameseNorm 無需依賴特定的引數微調,即可展現出超越基線的魯棒性與效能。
無懼高學習率
實驗表明,當學習率激進地提升至 2×10⁻³ 時,傳統的 Post-Norm 及 HybridNorm 架構均出現了不可逆的訓練發散。相比之下,SiameseNorm 展現了卓越的最佳化穩定性,不僅成功收斂,其訓練 Loss 更是顯著優於 Pre-Norm 基線,實現了高達 0.41 的 PPL 收益。
進一步的消融實驗揭示了其內在的協同增益機制:在同等實驗設定下,透過 Siamese 拓撲將"易發散"的 HybridNorm 流與"基線級"的 Pre-Norm 流(PPL 10.84)進行無任何輔助機制的直接耦合,模型取得了 10.68 的更優 PPL。這一結果有力地證明,Siamese 設計並非簡單的堆砌,而是成功實現了兩大正規化的互補,從而突破了單一正規化的效能天花板。
通用基準的全面提升與推理能力的質變
SiameseNorm 不僅在通用語言理解任務上確立了領先地位,更在邏輯推理中實現了突破。在 HellaSwag、OpenBookQA、PIQA 等涵蓋常識與知識問答的廣泛基準測試中,該模型均取得了最佳成績。
四、機制探究:各流的貢獻分析
研究人員首先透過提取兩條流中 LayerNorm 的可學習縮放引數,計算了它們對模組輸入的相對貢獻比例。實驗結果顯示,在絕大多數殘差塊中,兩條流均保持了顯著的權重佔比。這表明網路並未出現單側退化現象,而是有效地利用了來自兩端的隱藏表徵進行聯合特徵提取。
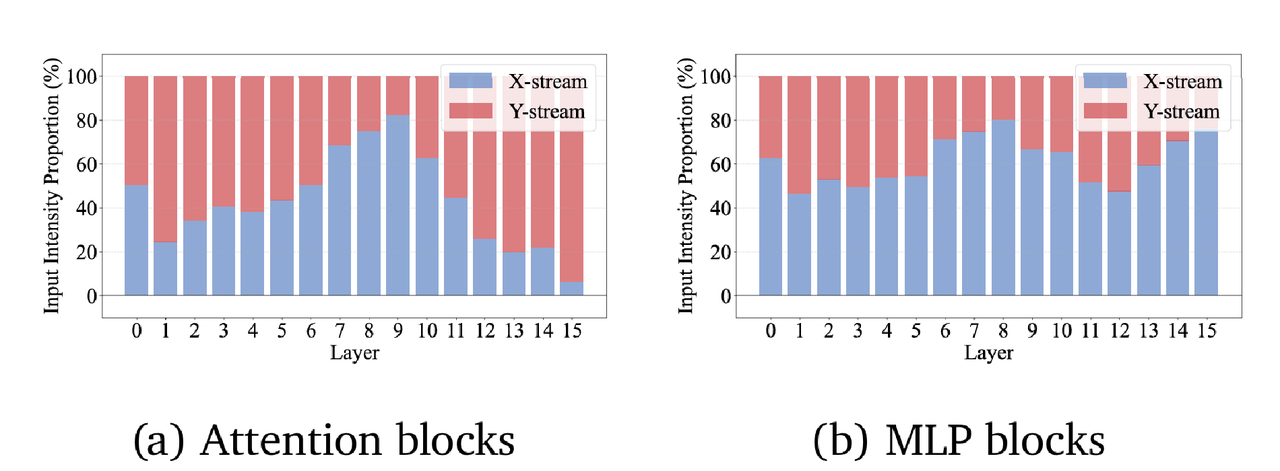
透過 Logit Lens 技術分析,研究人員發現了一個有趣的現象:在 SiameseNorm 的最終輸出中,Post-Norm 流(X流)佔據了主導地位,其對最終預測的貢獻度顯著高於 Pre-Norm 流。
上述現象支援了一種直觀的解釋:Pre-Norm 流主要充當了"訓練腳手架"的角色,負責在訓練初期保障穩定性;而一旦模型步入正軌,具有更強特徵表達能力的 Post-Norm 流的潛力便被釋放出來,在形成最終決策時發揮主導作用。
結語
長期以來,為了"跑得通",我們不得不接受 Pre-Norm 對有效深度的犧牲;而 Post-Norm 雖然更具表達潛力,卻又常因不穩定而難以進入大規模預訓練的主流配置。SiameseNorm 給出了一個優雅的答案:不再做選擇題。
它以近乎不增加成本的方式,把 Pre-Norm 的最佳化魯棒性與 Post-Norm 的表徵潛力統一在同一個框架內。對於追求更高學習率、更深網路、更強推理能力的大模型研發者而言,SiameseNorm 指明瞭一條清晰的路徑:讓 Transformer 走出"淺層困境",迴歸原始意義上的"深度學習"。