时光流转,在二十一世纪的今天,人工智能领域也有一对"双胞胎"——Pre-Norm(前置归一化)和 Post-Norm(后置归一化)。他们为解决大模型训练稳定性而生,迅速成为 Transformer 架构中用于稳定信号流的关键范式。
然而,归一化带来的训练稳定性并非没有代价,两种归一化范式之间似乎面临着难以调和的权衡取舍。尽管近年来 Pre-Norm 被 GPT-3、LLaMA、DeepSeek、Qwen 等知名开源基座所采用,但多项研究共同指向了一个严峻事实:Pre-Norm 架构存在严重的"深度失效"问题——大量深层参数虽在参与计算,却无法拓展模型的表征能力,致使模型的"有效深度"严重受限。与之相对的,尽管从表征能力角度 Post-Norm 拥有更高潜力,但其训练不稳定性在现代 Transformer 的预训练范式下是毁灭性的。于是,Pre-Norm 与 Post-Norm 这一对为解决同一难题而诞生的双胞胎,在各自追求"稳定"与"深度"的道路上分道扬镳。
近日,清华大学黄高 Leap Lab 团队联合千问 C 端团队给出了一份全新的答案 —— SiameseNorm。这一创新的孪生双流架构,巧妙地解耦了优化动力学:它并未在 Pre-Norm 与 Post-Norm 之间做二选一的取舍,而是构建了两条参数共享的平行通路。在这一架构下,一条流通过 Pre-Norm 机制保证训练的稳定性,另一条流则利用 Post-Norm 特性极大地释放模型的表征潜力。这种设计让每个残差块都能接收到来自两种范式的组合梯度,在几乎不增加计算开销的前提下,实现了高学习率下的稳定训练。这一精巧的双流协作,恰如默契的暹罗双胞胎,将两种范式的对立转化为深度融合的协同优势。
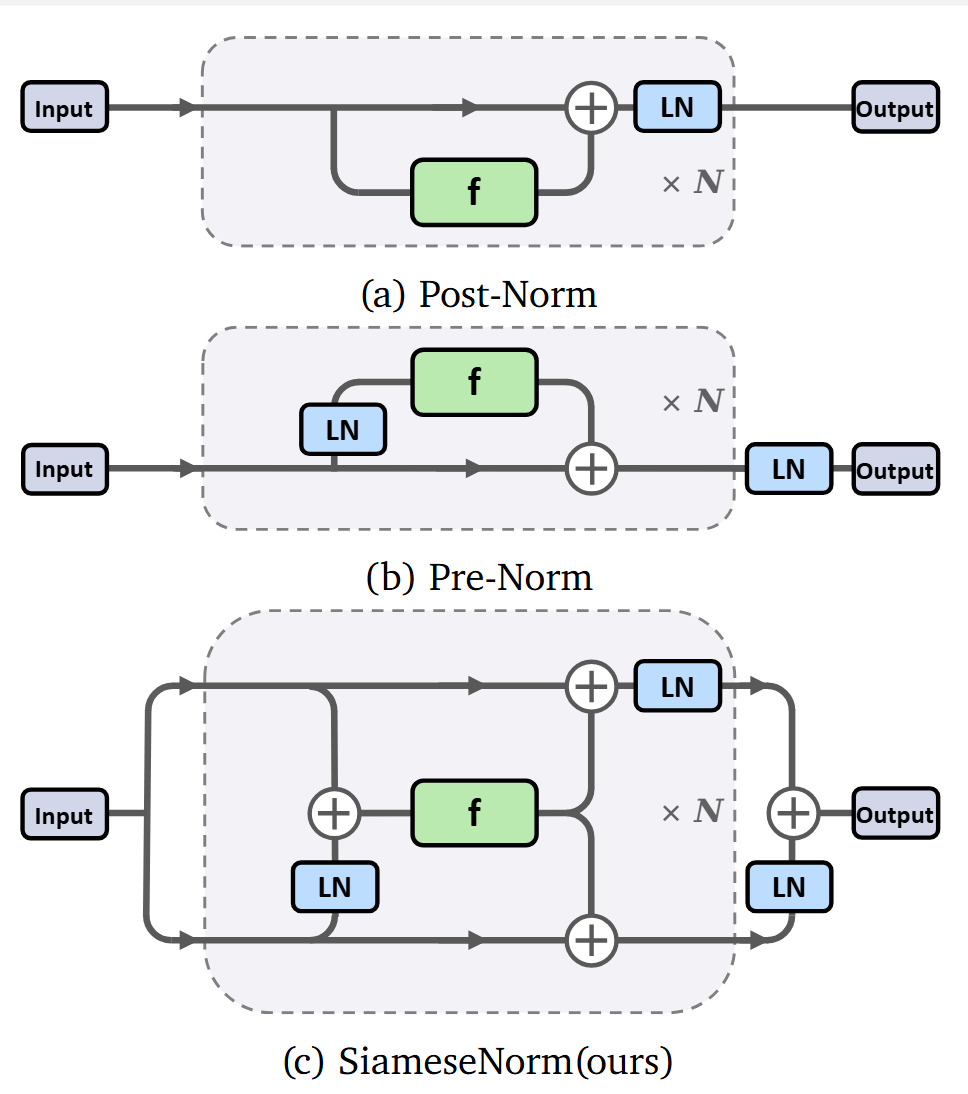
一、困境:单主干架构的先天缺陷与范式对立
前置还是后置?这仿佛是 Transformer 世界的"鱼与熊掌"。研究者不得不在"训练稳定但可能平庸"的 Pre-Norm 与"潜力巨大却难以驾驭"的 Post-Norm 之间做出艰难抉择。更令人困扰的是,任何试图在单主干架构中调和二者的努力,都遭遇了数学上的根本性障碍。
痛点 1:Pre-Norm 的"稀释"与 Post-Norm 的"畸变"
Transformer 的设计核心在于残差连接。然而,现有的两种主流范式都存在致命的结构性缺陷:
- Pre-Norm(稀释问题):为了保证梯度畅通,Pre-Norm
保留了一条干净的恒等路径。但这导致主干流的信号幅度随深度巨幅增长。到了深层,层归一化(LN)后的输入相对于巨大的主干流来说微乎其微,导致深层网络的贡献被"稀释",模型实际上退化成了"浅层"网络。最直观的实验证据来自于层剪枝实验:将
Pre-Norm 模型 30% 的层直接移除,在零微调的情况下,其评估指标竟几乎没有损失。
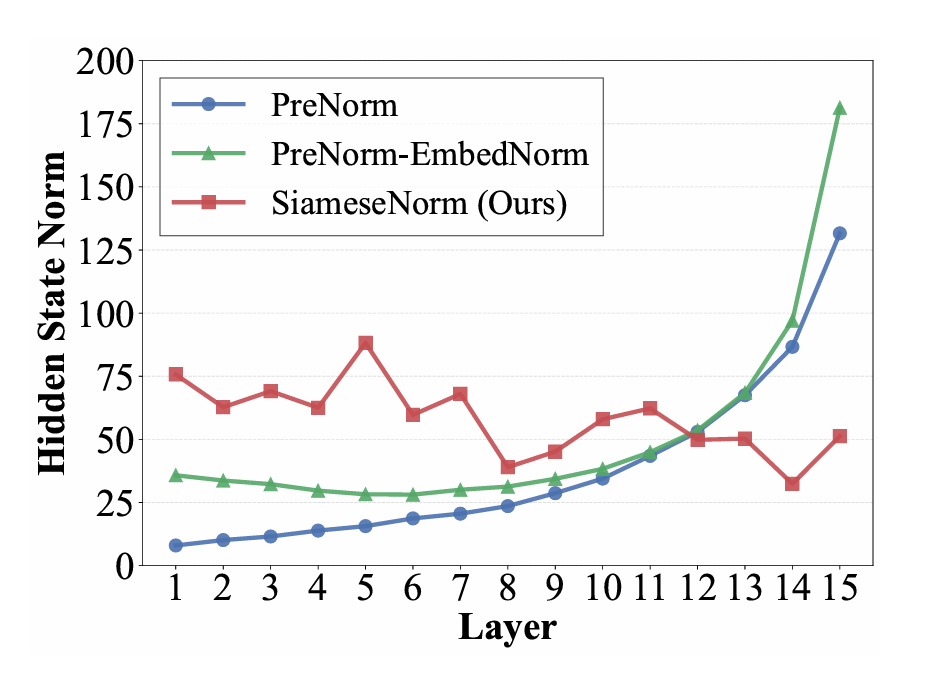
图2: 不同方法的隐藏状态范数随层数的变化曲线,可以看到Pre-Norm架构几乎是指数级增长 - Post-Norm(畸变问题):Post-Norm 强制在残差相加后进行归一化,保证了表示的效率,理论上限更高。但这也意味着它在每一步都在强行"压缩"信号,导致梯度的传导被破坏,容易引发梯度消失或爆炸。
痛点 2:两大范式的不可兼容性
目前的混合方案试图在两者间寻找平衡,但论文深刻地揭示了,这两种结构在单主干设计中本质上是互斥的:
- 梯度的"无损传输" vs. 信号的"尺度束缚":Pre-Norm 的稳定性依赖于保留严格的恒等路径,这意味着必须允许信号幅度在主干中自然增长。相反,Post-Norm 的高效性依赖于严格规范,即在主干中通过归一化限制信号幅度。
- 单主干的理论极限:论文指出,在共享同一条主干路径的前提下,在数学上不可能同时做到两件事:既保留一条完全干净、不受阻碍的梯度通道,又同时对主干信号强制施加严格的幅度约束。
任何试图在单主干结构内强行融合两者的尝试,最终都只能是一种"妥协":它们不仅无法兼得二者之长,反而继承了 Post-Norm 的不稳定性。要打破这个僵局,必须从结构上进行彻底的解耦。
二、破局:SiameseNorm 的双流解耦之道
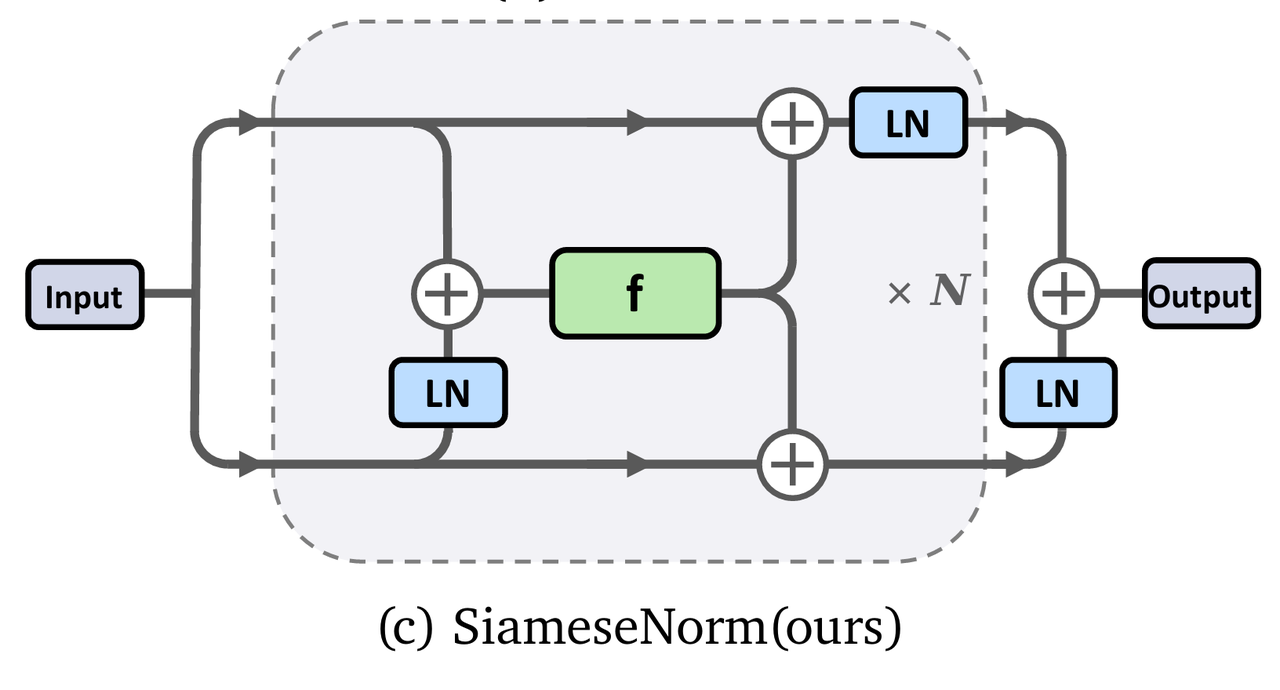
SiameseNorm 的核心洞察在于:我们无法在单一信号流中同时满足"梯度传导"和"表示规范"这两个互斥的需求。因此,SiameseNorm 引入了"孪生双流"(Siamese)机制:
从结构图中也可以看出,把下一半遮住,它退化成 Post-Norm;把上一半遮住,它退化成 Pre-Norm。而在训练过程中,LayerNorm 的可学习权重可以调整两条流的大小关系。通过将支流上的 LayerNorm 调整为 0,可以退化成现有的 Pre-Norm、Post-Norm、Mix-LN 范式。
这一架构的核心在于高效的"参数共享"机制:双流路径并非独立存在,而是共享残差块的权重。这意味着 SiameseNorm 几乎没有带来参数量与计算的增长。为降低这种耦合结构的训练难度,架构中进一步引入了 Normalized Input(归一化输入) 与 Depth-wise Scaling(深度缩放),有效解决了参数共享的双流架构带来的优化对齐挑战。
三、硬核实测:拯救 Post-Norm,数学任务暴涨 40%
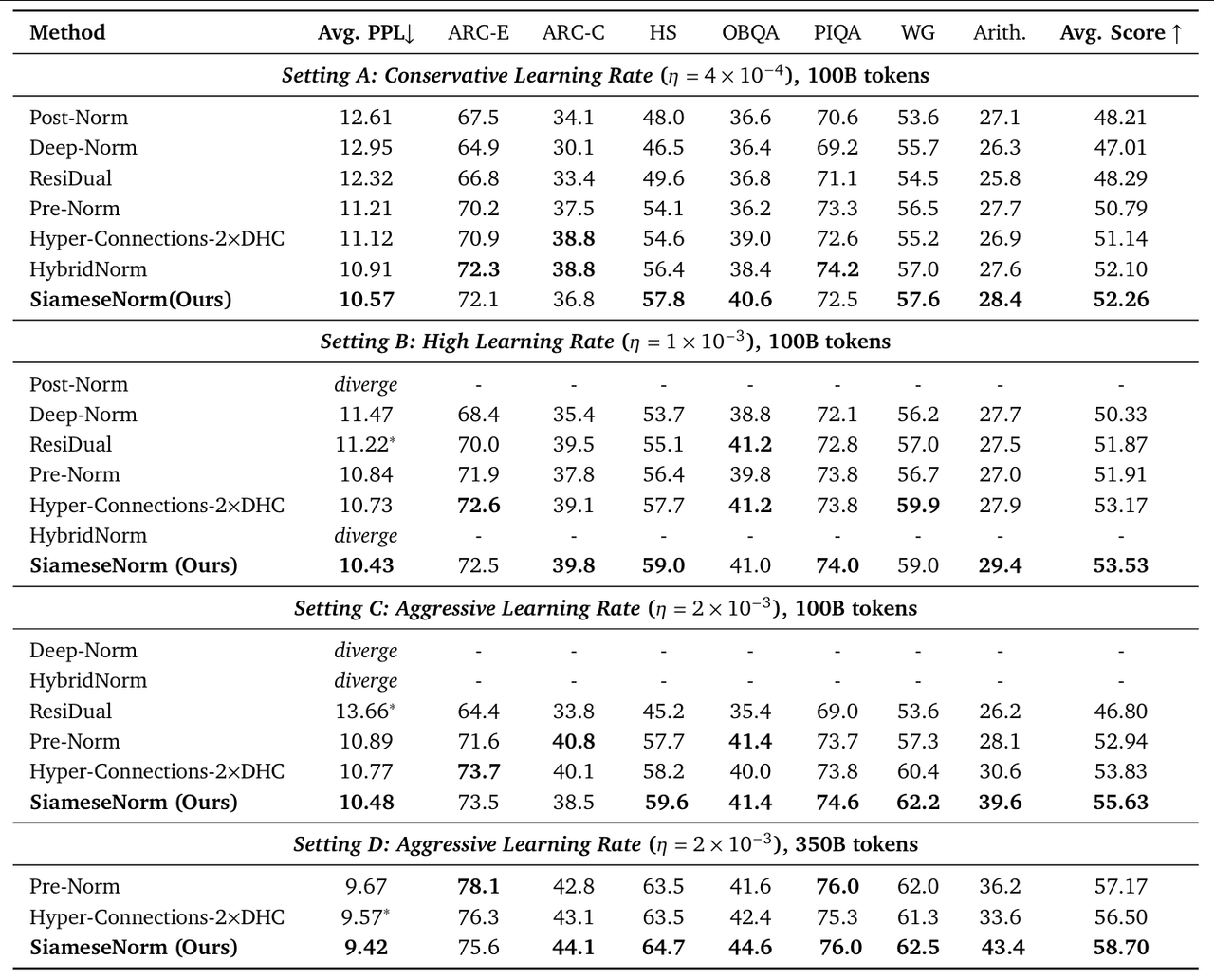
在 1.3B 参数模型、100B/350B tokens、总计算成本超过 50,000 A100 GPU 小时的预训练实验中,SiameseNorm 展现了惊人的统治力:
直面公平对比的挑战
研究者首先在不同的学习率下对比了现有各种 Pre-Norm 和 Post-Norm/HybridNorm 变体的表现,发现两类范式的最优学习率存在显著差异,这揭示了一个长期被忽视的问题:超参(尤其学习率)的选择足以改变架构对比的结论。换言之,过往许多研究因未能适配 Pre-Norm 的最优配置,实际上人为地压低了基线的性能天花板,从而制造了"性能显著提升"的假象。
因此,一个公平的比较应该对不同方法分别做超参搜索,而这在大模型预训练中成本极高。在本篇论文中,研究者直接沿用了主流 Pre-Norm 的训练超参。这一策略旨在证明,SiameseNorm 无需依赖特定的参数微调,即可展现出超越基线的鲁棒性与性能。
无惧高学习率
实验表明,当学习率激进地提升至 2×10⁻³ 时,传统的 Post-Norm 及 HybridNorm 架构均出现了不可逆的训练发散。相比之下,SiameseNorm 展现了卓越的优化稳定性,不仅成功收敛,其训练 Loss 更是显著优于 Pre-Norm 基线,实现了高达 0.41 的 PPL 收益。
进一步的消融实验揭示了其内在的协同增益机制:在同等实验设置下,通过 Siamese 拓扑将"易发散"的 HybridNorm 流与"基线级"的 Pre-Norm 流(PPL 10.84)进行无任何辅助机制的直接耦合,模型取得了 10.68 的更优 PPL。这一结果有力地证明,Siamese 设计并非简单的堆砌,而是成功实现了两大范式的互补,从而突破了单一范式的性能天花板。
通用基准的全面提升与推理能力的质变
SiameseNorm 不仅在通用语言理解任务上确立了领先地位,更在逻辑推理中实现了突破。在 HellaSwag、OpenBookQA、PIQA 等涵盖常识与知识问答的广泛基准测试中,该模型均取得了最佳成绩。
四、机制探究:各流的贡献分析
研究人员首先通过提取两条流中 LayerNorm 的可学习缩放参数,计算了它们对模块输入的相对贡献比例。实验结果显示,在绝大多数残差块中,两条流均保持了显著的权重占比。这表明网络并未出现单侧退化现象,而是有效地利用了来自两端的隐藏表征进行联合特征提取。
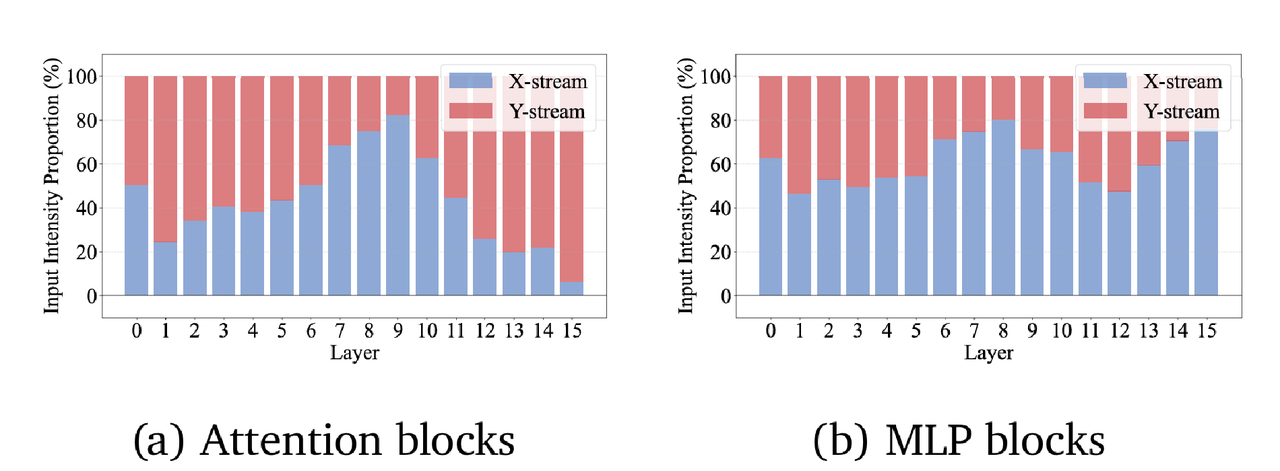
通过 Logit Lens 技术分析,研究人员发现了一个有趣的现象:在 SiameseNorm 的最终输出中,Post-Norm 流(X流)占据了主导地位,其对最终预测的贡献度显著高于 Pre-Norm 流。
上述现象支持了一种直观的解释:Pre-Norm 流主要充当了"训练脚手架"的角色,负责在训练初期保障稳定性;而一旦模型步入正轨,具有更强特征表达能力的 Post-Norm 流的潜力便被释放出来,在形成最终决策时发挥主导作用。
结语
长期以来,为了"跑得通",我们不得不接受 Pre-Norm 对有效深度的牺牲;而 Post-Norm 虽然更具表达潜力,却又常因不稳定而难以进入大规模预训练的主流配置。SiameseNorm 给出了一个优雅的答案:不再做选择题。
它以近乎不增加成本的方式,把 Pre-Norm 的优化鲁棒性与 Post-Norm 的表征潜力统一在同一个框架内。对于追求更高学习率、更深网络、更强推理能力的大模型研发者而言,SiameseNorm 指明了一条清晰的路径:让 Transformer 走出"浅层困境",回归原始意义上的"深度学习"。